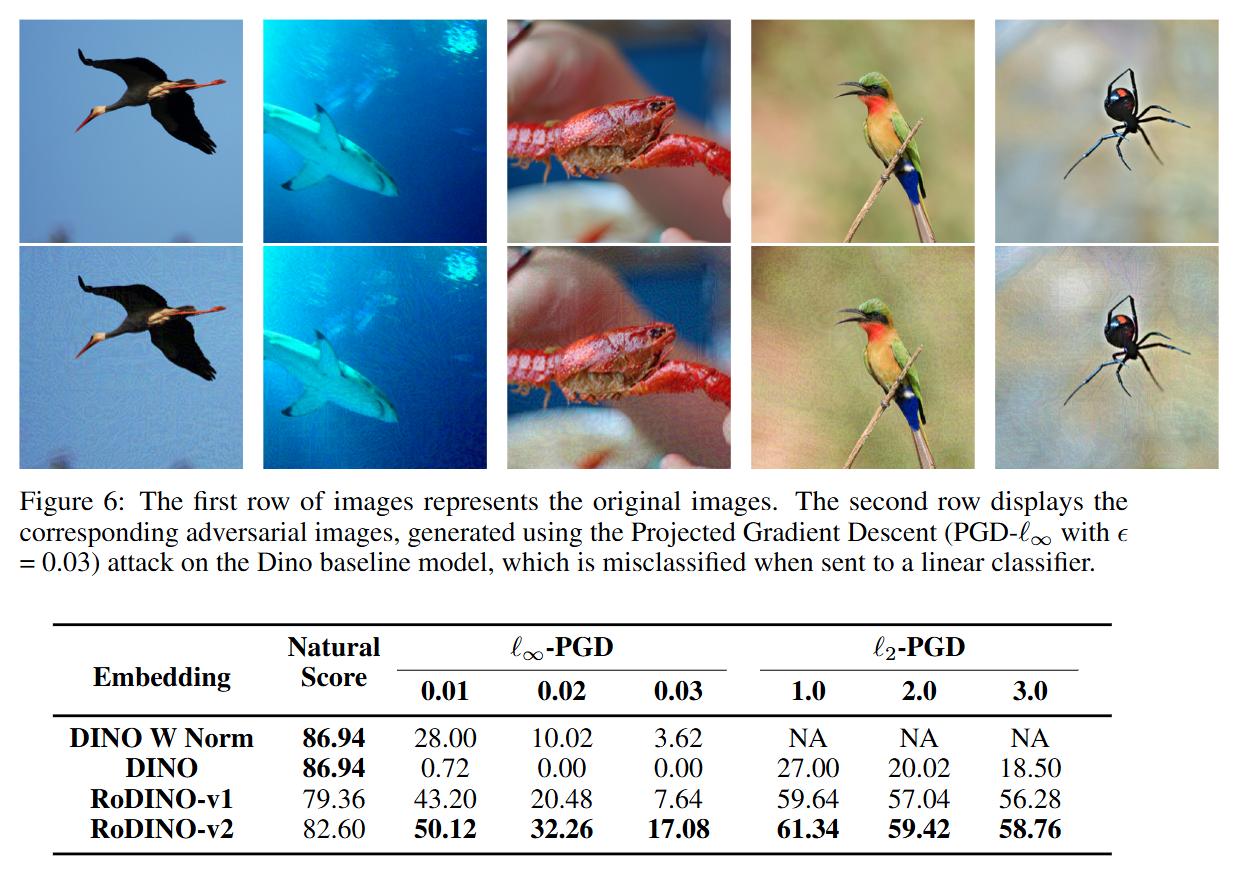
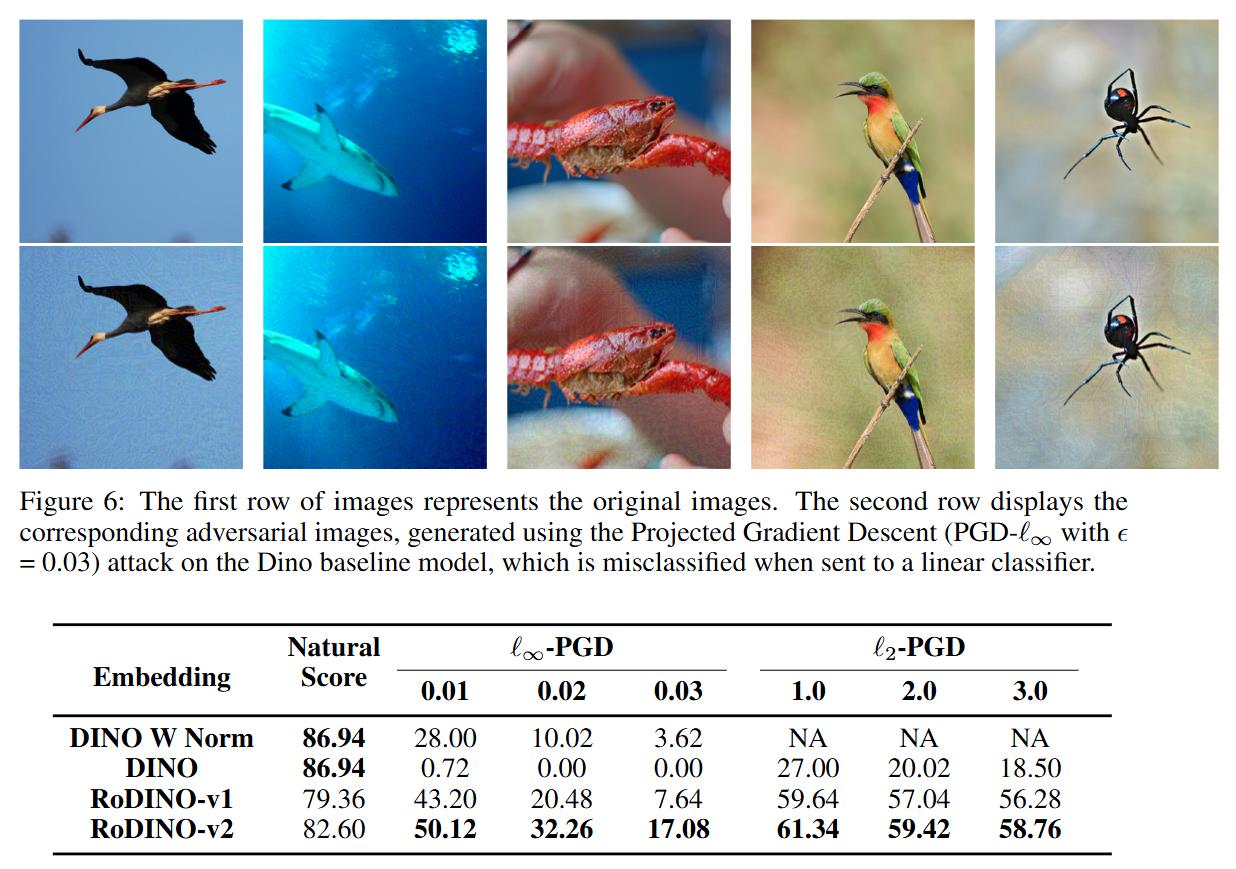
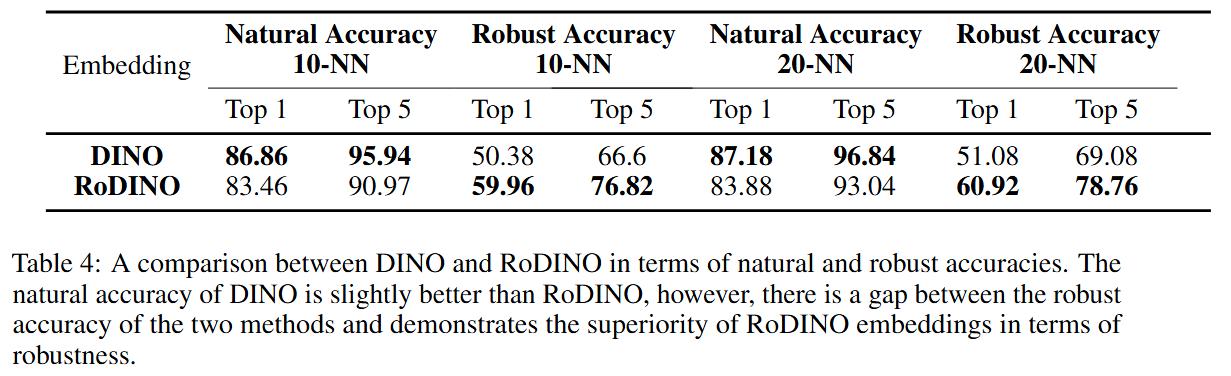
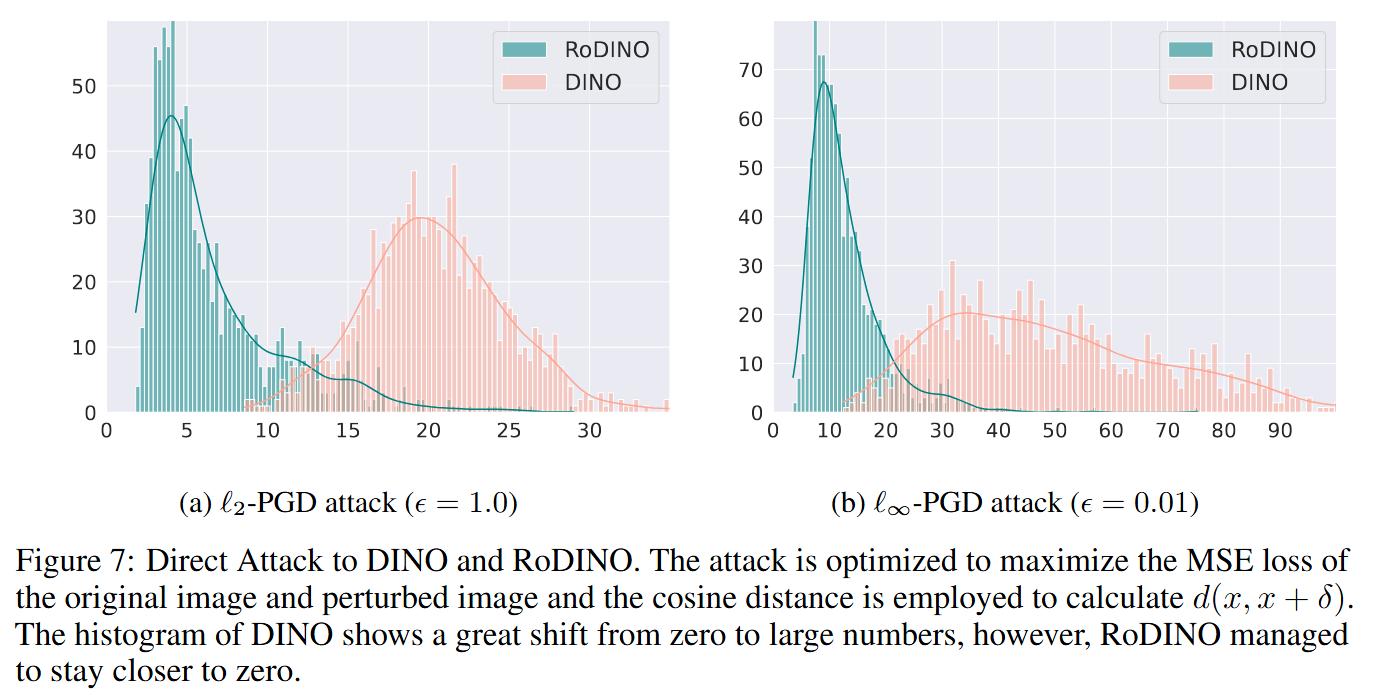
Robust DINO (DINO adversarial robustness using adversarial training) (2023)
You can find the full project report Here.
Our paper abstract:
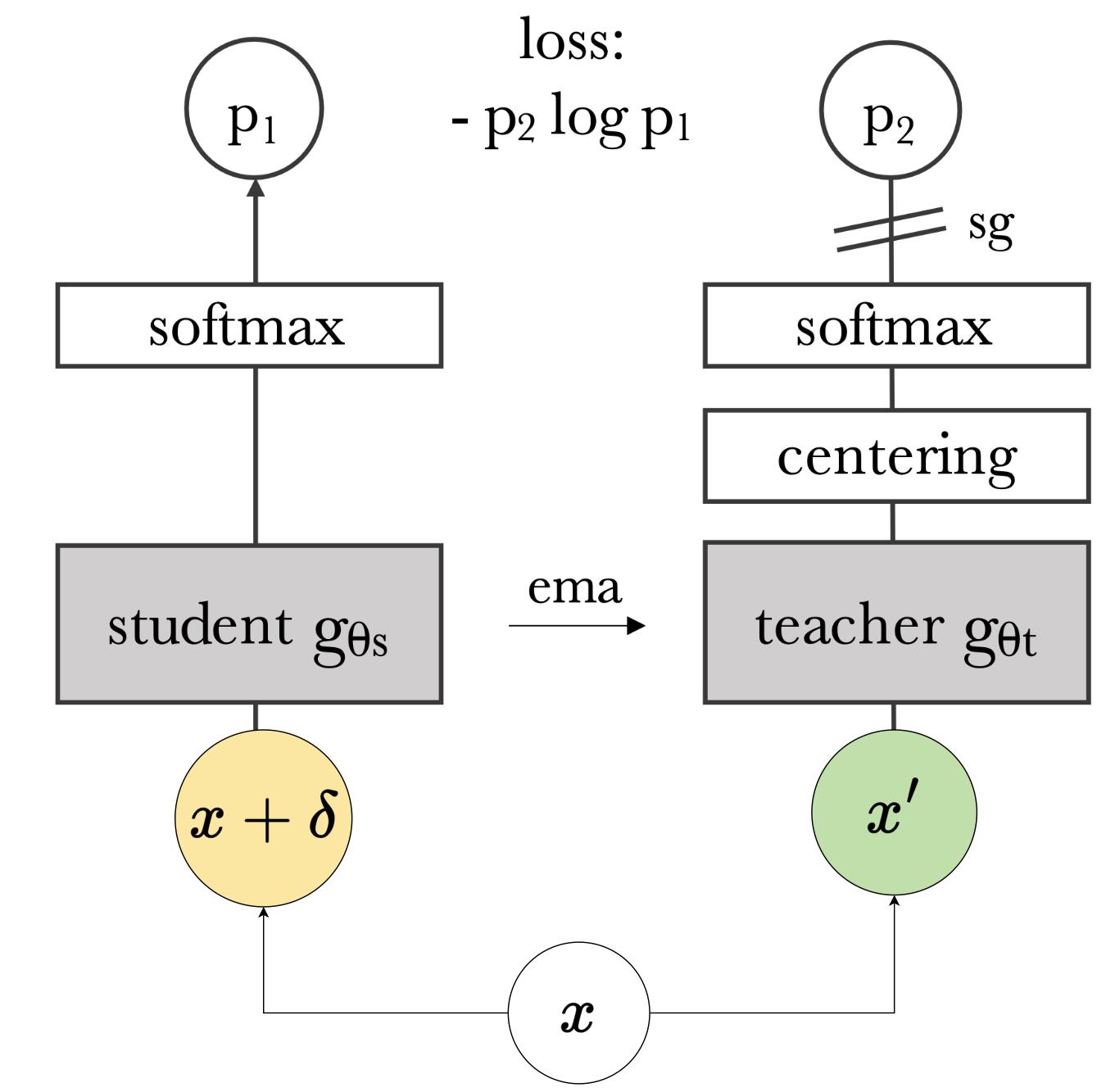
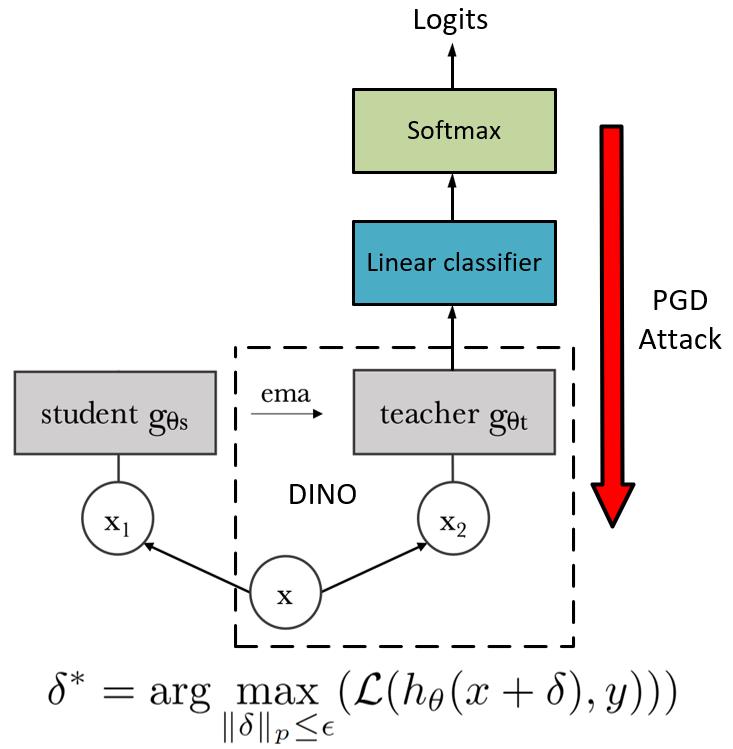
Recently, learning task-agnostic representations using foundation models has gotten great attention in computer vision. Rich representations learned using foundation models are showing impressive performance on several downstream tasks including classification, segmentation, Image retrieval, etc. On the other hand, as it's well known, Neural Networks are vulnerable to adversarial attacks. The vulnerability of foundation models to adversarial attacks harms the performance of the model to all of the downstream tasks, and therefore having a robust representation can have a huge impact on the robustness of all tasks. Considering this fundamental impact, in this project, we propose RoDINO (Robust DINO) which is a method to boost the empirical robustness of downstream tasks by leveraging PGD attack to generate adversary images and adversarially train DINO which is a self-supervised representation learning model with Vision Transformers backbone.
Our Work Album (Click to see all images)